
保护私人版权,尊重他人版权。转载请注明出处并附带页面链接
《大数据从懵逼到入门》主要是对大数据相关技术进行介绍,并且完全基于大数据开发规范和工具完成一个简单的Demo,一起从懵逼到入门。
什么是大数据
从字面意思上大数据是指海量数据,无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
其实大数据是一个概念也是一门技术,它包括了以Hadoop和Spark为代表的基础大数据框架,还包括MapReduce编程模型,离线数据处理;数据分析,数据挖掘,使用机器学习算法进行预测;分布式文件系统,分布式数据库等技术。
其中有两个最关键的技术:
- 分布式文件系统:存储是大数据技术的基础
- MapReduce编程模型:分布式计算是大数据应用的解决方案
本期先对分布式文件系统HDFS进行介绍,接下来会介绍MapReduce与Hadoop。
==========我是分割线==========
不知道大家会不会有这么一个疑问:为什么要使用分布式文件系统?传统的文件系统不行吗?
举个🌰:我想存储一个100M的文件,可以怎么做。
一般大伙会觉得这有什么的,直接存就好了。
那现在问题升级一下,假如我有一个100T的文件呢?100P呢?
我们都知道,linux文件系统对单文件大小是有限制的,如果是ext3文件系统块大小是4K的话,那么最大可以支持的单文件尺寸是2T,而且有一块大于2T的存储硬件,显然无法满足我们的需求。此时分布式文件系统就可以发挥它的威力,分布式文件系统就是为了这样的海量数据存储而存在的。
分布式文件系统 HDFS
HDFS是Hadoop分布式文件系统,它是一个高度容错性的系统,适合部署在成百上千台普通的机器上,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
从对HDFS的描述中不难发现有几个重点:高度容错性、高吞吐量和大规模数据集。
高度容错性:指的是硬件错误是个常态而不是异常。HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据,但是任意一个服务器都可能失效,所以需要保障当一部分机器出现问题时,集群依然能为外部提供正确的服务。因此错误检测和快速、自动的恢复是HDFS最核心的架构目标。
高吞吐量:运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。
大规模数据集:运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
为了满足大多数大文件的需求和大数据处理的特定场景,HDFS在设计时也做了一定取舍,当然也带来了很多不便:
- 不适合大量小文件存储
- 不适合并发写入
- 不支持文件随机修改
- 不支持随机读等低延迟的访问方式
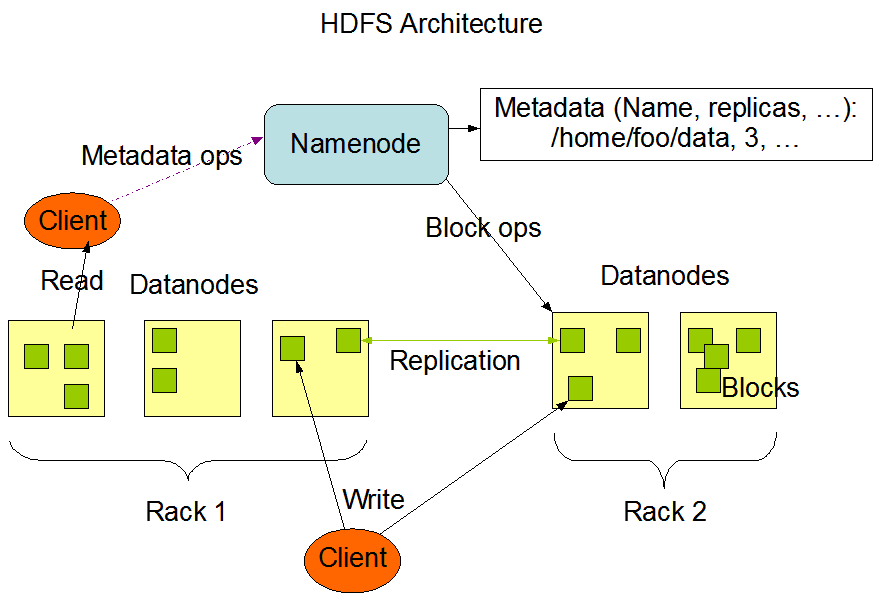
Namenode与Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的命名空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS对外仅暴漏文件名,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,数据块存储在一组Datanode上。
Namenode不仅负责执行文件系统的操作,比如打开、关闭、重命名文件或访问目录,它也负责确定数据块到具体Datanode节点的映射。
Datanode负责处理文件系统客户端的具体读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。当客户端读取数据时,首先向Namenode请求到命名空间以及文件数据块所在多个Datanode的地址,再由客户端直接向Datanode发起数据读取请求,整个过程中Namenode都是没有元数据流通的。
数据块是将一个文件根据固定大小分解成的小块,所以在HDFS中并不是将整个文件作为存储单元。数据块一般大小64MB,可以按需调节;同一个数据块一般也会设置多份副本,副本也会分布在不同的Datanode上以保证高度容错性。
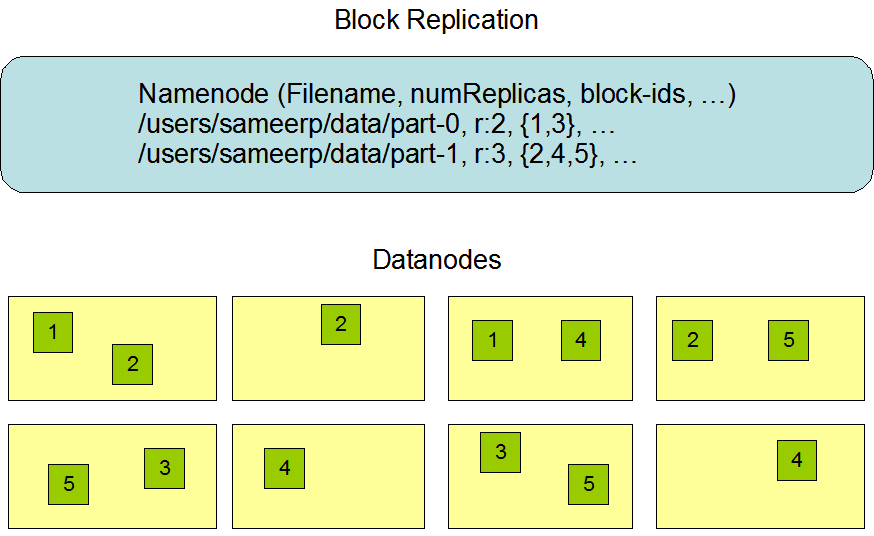
数据复制
HDFS在被设计能够在超大集群中存储超大文件的系统,并且在廉价机器上同样可以保证可靠。他将所有的文件都分解成一系列大小相同的小数据块,除了最后一个的数据块大小是余数。为了保证可靠,每一个数据块都会存在多个副本,开发者可以根据自己的需要在文件创建时,或者文件使用过程中设置需要副本的数量。
HDFS通过规定所有的文件都要一次性写入,每个时刻都只能存在一名写入者保证了文件存储绝对可靠。
数据块的复制也由Namenode管理,Namenode会轮询集群中的每一个Datanode,获取各个Datanode的心跳和节点中所有数据块状态。
启动HDFS
HDFS搭建指南在网上有很多,这里就不再赘述,我在搭建的过程中遇到了一些问题,不过通过检查报错日志都一一解决了。
折腾了一下午我的Namenode、Datanode都没起来,而且启动过程出错也没有抛出异常,注意到有日志后5分钟(手动笑脸)
日志记录的还是很详细的,可以看到hadoop运行过程中各个组件的运行和报错的情况。
使用HDFS
HDFS允许使用Web接口和Shell命令对HDFS直接操作。
Web接口
Web接口默认配置使用http://localhost:9870/访问本机Namenode,这个页面展示了集群中各个Datanode的情况,也可以用来浏览整个文件系统。
查看各个node状态

查看文件系统内容

Shell命令
HDFS的Shell命令使用起来跟linux文件系统命令基本上一致,多了HDFS独有的put和get命令,put是从本地文件系统上传文件到HDFS,get与put相反。
1 | 查看目录内容 |
验证一下数据块
我使用put命令向HDFS中上传了hadoop-3.2.0.tar.gz大小是330MB,现在进入到Datanode的数据目录中看一下存储情况。
1 | 我先前配置hdfs时指定了Datanode目录在/home/hadoop/dfs/data/ |
可以看到我刚才上传的hadoop-3.2.0.tar.gz已经变成了三块数据blk_1073741828、blk_1073741829、blk_1073741830分别是两个128M,一个74M,检查一下hdfs的默认块大小
1 | <property> |
的确是128M。
hadoop官方文档中说”一个典型的数据块大小是64MB”,我使用的是hadoop3.2,这里默认数据块大小是128MB。实际上是因为hadoop1.x的HDFS默认块大小为64MB;hadoop2.x的默认块大小为128MB。
一句话总结
HDFS的出现解决了使用廉价机器建立集群存储海量数据的问题,可以说为大数据领域打开了一扇窗。
