
保护私人版权,尊重他人版权。转载请注明出处并附带页面链接
理解跳跃表
概念
跳跃表是一种数据结构。其允许快速查询一个有序连续元素的数据链表。而且跳跃列表的平均查找和插入时间复杂度都是O(log n),比常用的线性结构链表,数组这类的时间复杂度O(n)要优秀很多。
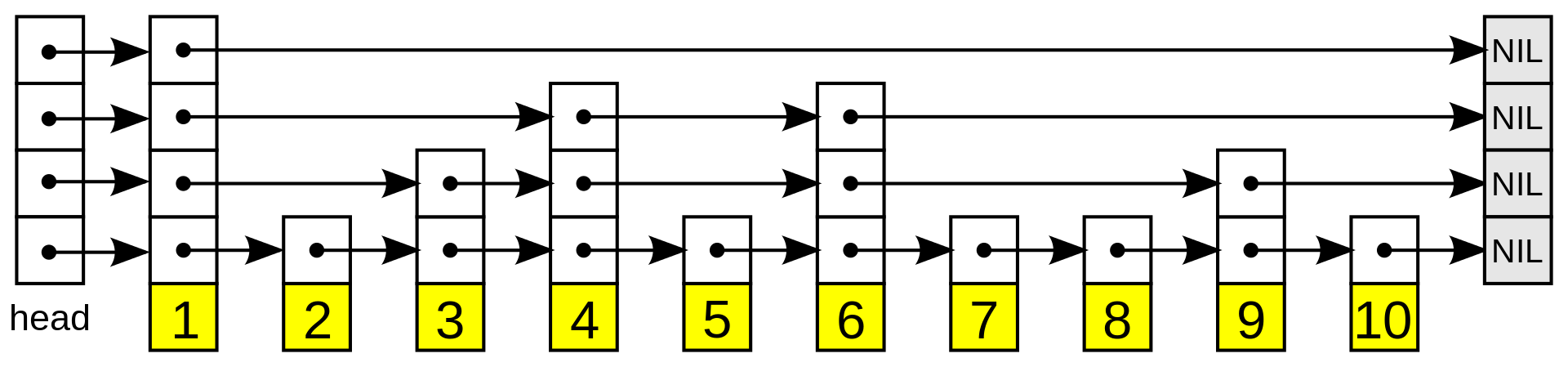
其结构如图所示:
![image.png-61kB][1]
每个带有箭头的框表示一个指针, 而每行是一个稀疏子序列的链表;底部的编号框(黄色)表示有序的数据序列。查找从顶部最稀疏的子序列向下进行, 直至需要查找的元素在该层两个相邻的元素中间。
##增加元素
对于跳跃表来说,当向表中增加一个元素时其会通过最顶层的索引一层层往下找,由于建立索引的关键节点几乎是下一层的一半,所以在查找索引的过程需要比较的元素数目相比于直接去查找源链表一次会减少一半的查询次数,即总的时间复杂度会为O(log n)。
具体过程是这样的:
1 | st=>start: 开始 |
##删除元素
跳跃表删除元素的操作是这样的,自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。总体上,跳跃表删除操作的时间复杂度是O(logN)。
![image.png-79.1kB][2]
5为需要删除的节点。
##总结
跳表的结构定义:
1 | ype head struct { |
对于跳表其实可以使用一个指针数组保存每一级别的头节点,每个元素节点存在两个指针一个指向链表的下一个元素一个指向上级索引这种方式来实现。查找和修改的操作基本步骤和上面的删除添加差不多。我们日常熟悉的redis中也有对其使用,相比于平衡树其具有易于维护的特点。

{kind=link}
{kind=link}